By Adrian | November 28, 2019
Now that I’ve gone through a series on TheHive, I’ve started to expand on the capabilities of this DFIR platform by starting to write my own Responders. Responders are essentially a way to perform an enhancement action on a given case, alert or observable.
The built in Responders from the Cortex GitHub repo include a responder that will email the case or alert details to you as well as responders that interface with CrowdStrike, QRadar, Umbrella and ZeroFox. The only limit to what is possible here is your imagination. If the system you want to connect to has an API interface to perform an action (such as block an IP on your firewall, IDS/IPS, WAF etc) then you can code up a responder accordingly. Even if you want to perform some kind of standalone action, you can do that as well.
TheHive-Project maintains documentation on how to create a responder which is a great starting point if you want to go down this path.
In this instance, I created a responder that will simply create a Markdown report of a case you run the responder against. It can be useful to provide some sort of report to management or as a post mortem at the conclusion of an incident when giving people outside your team access to TheHive isn’t necessarily what you want to do.
To install this Responder (and all future responders in my repository), there are a few options.
Standalone files
If you choose to not trust the content I publish (and you shouldn’t) you can grab a copy of the files from https://github.com/aacgood/Cortex-Analyzers/tree/master/Responders/Reporter and put them in a directory of your choosing on your Cortex server.
Git Method
If you want an easy way to grab new changes then using git is the way to go. It would also be the way I recommend if you are building your own analysers and responders.
First SSH to your Cortex server and create a directory (in this case I am using /opt/cortex/github-aacgood)
Clone the repository
cd /opt/cortex/github-aacgood
git clone https://github.com/aacgood/Cortex-Analyzers.git
Configuration update
After choosing either the standalone or git options, update application.conf to tell Cortex where a new responder repository is. This will be under the responder config block.
responder {
path = [
"/opt/Cortex-Analyzers/responders/",
"/opt/cortex/github-aacgood/Cortex-Analyzers/Responders"
]
}
Finally login to the Cortex interface, select Organization, Responder, Refresh Responders. If the responder does not turn up, check the permissions of the files and try refreshing again.
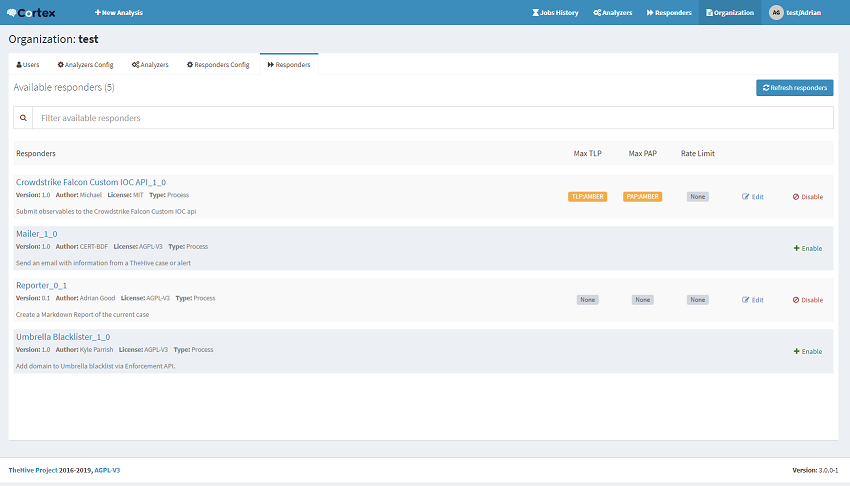
Running the responder
Within TheHive the responder will become available immediately. This responder can be accessed from within a case.
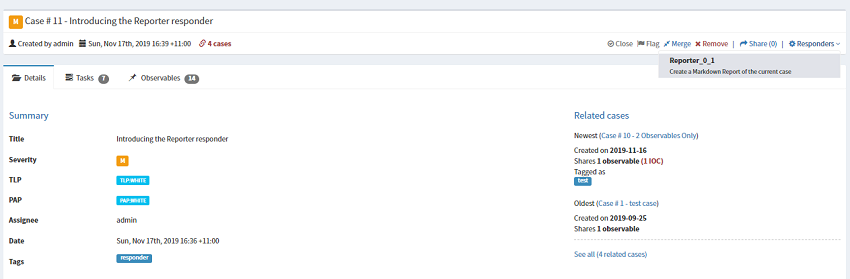
The report file will be saved within the case under the attachments for download. There are plenty of tools that can convert Markdown into HTML/Word/PDF etc.

Here is a screenshot of part of the report.
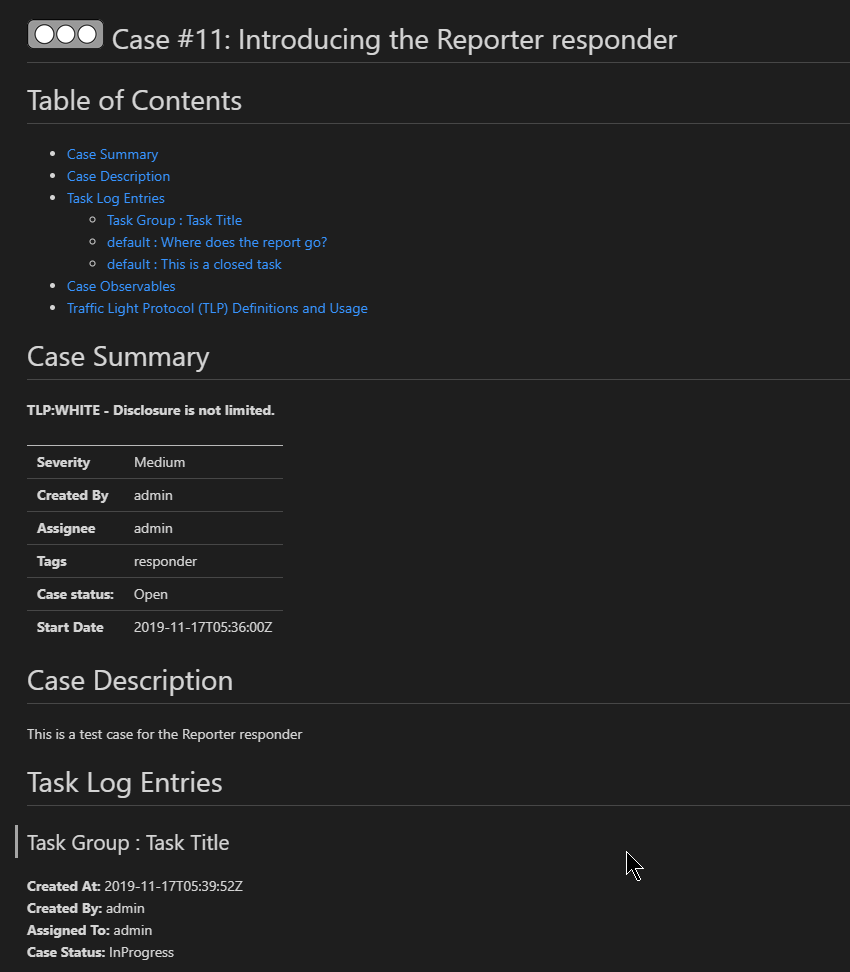
Under the hood
The responder is written in python and requires the use of mdutils which generates the Markdown. The other imports are for collecting all the observables in the case, the tasks and the task log entries.
from cortexutils.responder import Responder
from mdutils import MdUtils
from thehive4py.api import TheHiveApi
from thehive4py.models import Case, CaseTask, CaseTaskLog, CustomFieldHelper
The script then proceeds to generate the title, case summary, case description, task logs, case observables puts a copy of the TLP protocols on a new page and creates a table of contents. Finally the generated Markdown is saved back into the case for download.
Looking at the raw Markdown file looks a bit like rubbish, as the TLP images are being stored as base64 images within the Markdown file. This was done so that the TLP images didn’t need to be stored with the document and that the report was all encompassing. It does come out ok when rendered, promise ;-)
Conclusion
This isn’t the first crack I’ve taken at a responder, but its the first one ive made public. There were a few curly bits of python in there when it came to how the data was extracted and how to sort it. In the end, I think it serves its purpose. Would this something your organisation or team would find useful? I’m happy to take suggestions or improvements, even happier if you want to submit a pull request or bug report. I consider this responder a first pass and im sure there is probably more that could be included.
Please feel free to reach out to me if you need some assistance and I will see what I can do.