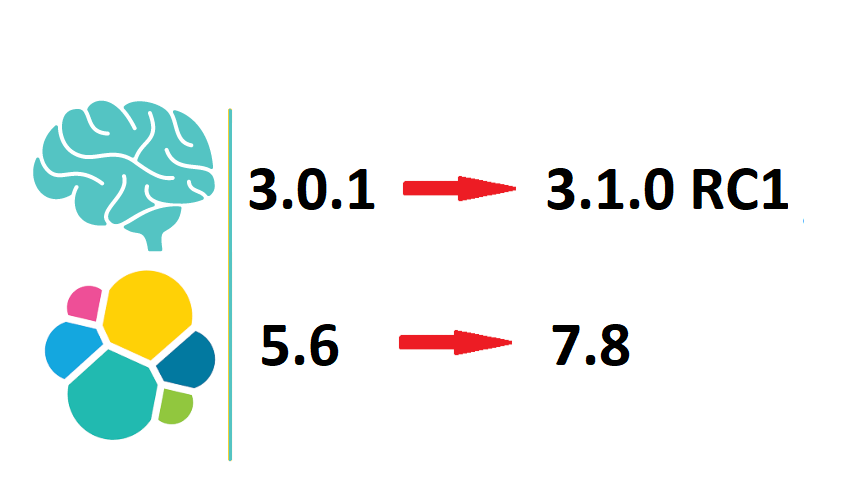
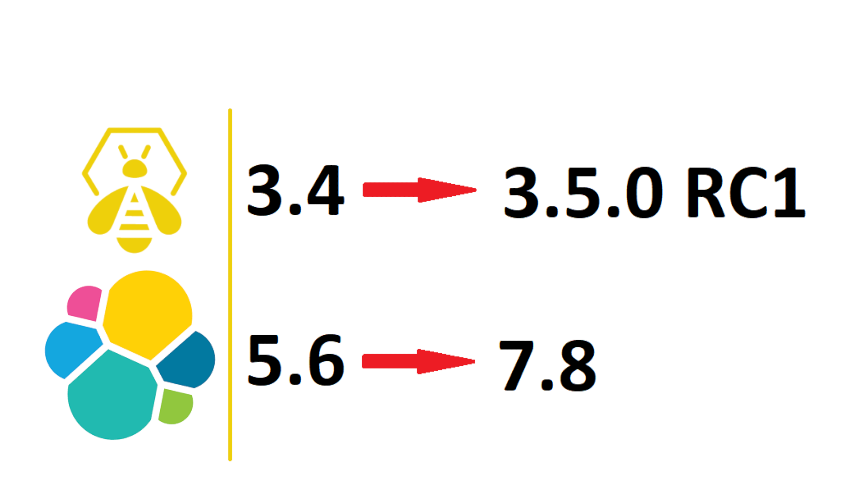
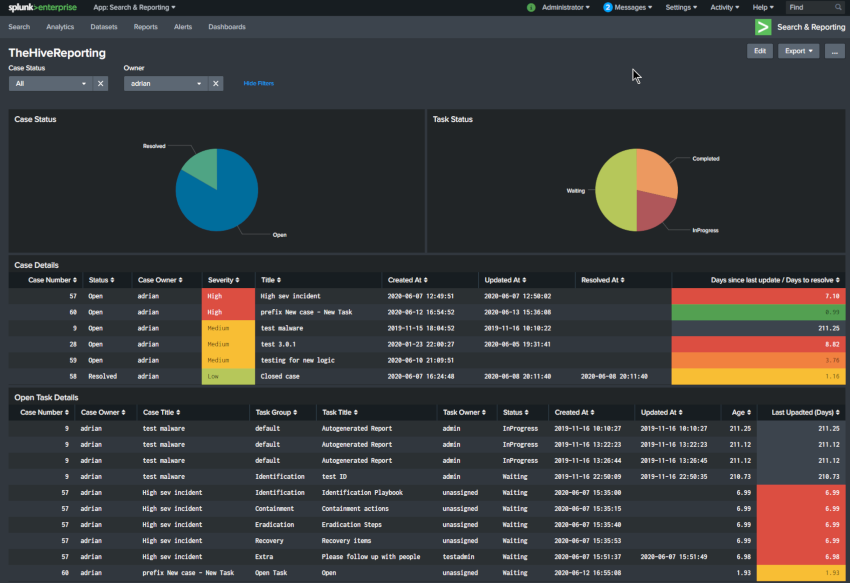
Thehive5 Webhooks
When it comes to online applications some of the best functionality comes when you can programmatically tap into it as it creates countless opportunities to customise and extend the functionality to suit your needs without having to modify the underlying application. In the Context of TheHive, the API will allow you to query, post or search data which can aid in the lifecycle of an incident as well as create alerts and cases programmatically.