By Adrian | June 14, 2020
TheHive dashboards, while they are great at showing data counts and displaying then as graphs, there is one feature that was lacking in that it cant display a data table of what those cases are. So while you can build a dashboard to get a snapshot of where your team is at, you can’t see what cases and task that are in play.
While there is an open issue to add this functionality, I thought i’d try something a little different with TheHive to fill that gap, and export the case and task data into a Splunk kvstore and build it out that way. While TheHive still uses elasticsearch (ie: TheHive v3 and earlier), you could also get to this data easily using Kibana.
For this solution, there are 2 potential ways doing this.
- Use TheHive webhooks so that when any case or task is created, modified or closed that a call is made to write the request into Splunk
- Create a script on a schedule to query the data out of TheHive and then write it into Splunk.
I chose to use the second option as it would give me some more exposure into python scripting, thehive4py module and the Splunk API. However, if you were looking at doing this in a proper production environment, you would need a combination of a script to initially generate the data (if you wanted historical data), and then the webhooks to update them in near realtime.
The Setup
I have a clean install of Splunk Enterprise, with the Lookup Editor app installed. You will also need the python-splunk-sdk.
Create the kvstore
Create a new kvstore in Splunk opening up the Lookup Editor app and selecting Create a new lookup, kvstore. Give the kvstore a name (TheHiveReporting) and select the app that it is to be associated to (Search & Reporting). If your feeling a little more hardcore, you could just make the changes to the collections.conf file directly.
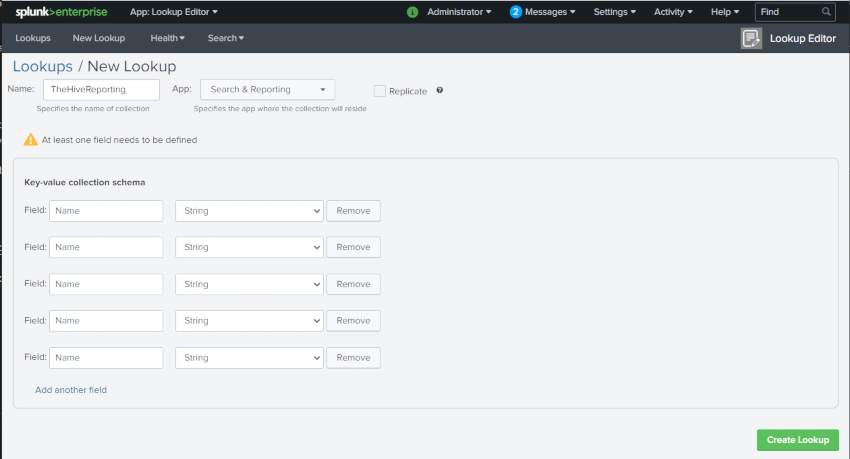
Now add in the fields you are after. For field mapping, I have prefixed cases with case and tasks with task. Custom fields in TheHive provided an extra little challenge, I have just called them caseCfield1, caseCfield2, caseCfield3, but make them useful for you.
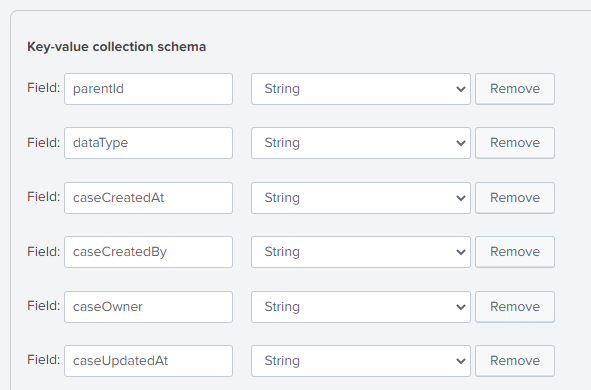
The full list of fields I added were:
parentId,dataType,caseCreatedAt,caseCreatedBy,caseOwner,caseUpdatedAt,caseUpdatedBy,caseEndDate,caseStatus,caseNum,caseTitle,caseDescription,caseSeverity,caseResolutionStatus,caseImpactStatus,caseCfield1,caseCfield2,caseCfield3,taskTitle,taskOwner,taskCreatedAt,taskCreatedBy,taskUpdatedAt,taskUpdatedBy,taskStatus,taskGroup
Should you need to update the kvstore fields after you have created it, you will need to modify the $SPLUNK_HOME/etc/apps/search/local/collections.conf file and restart Splunk.
Update the lookup definitions
After the kvstore has been added you need to update the lookup definitions. In Splunk navigate to Settings, Lookups, Lookup Definitions. Press the New Lookup Definition button. Ensure you have the correct details for Destination app, Type, Collection Name and Supported fields.
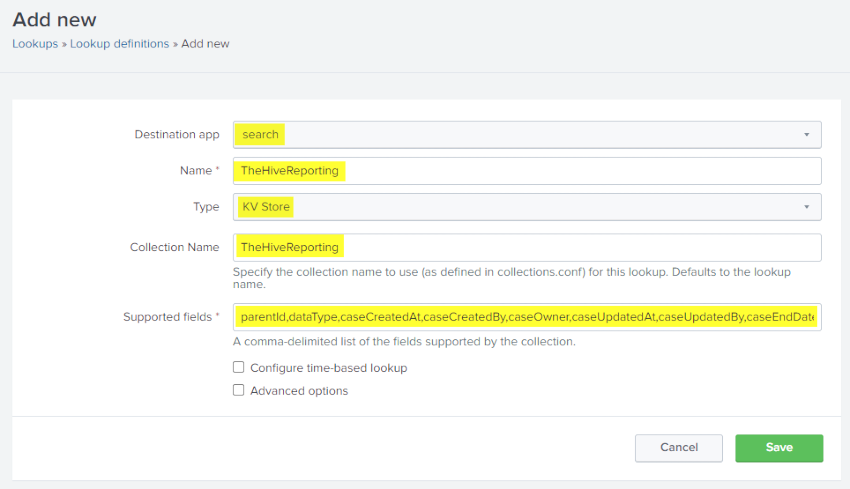
If you add anymore fields into your kvstore, remember to update the lookup definition as well.
The Script Pre-Reqs
This is where all the magic happens, but there are a few configurations we need to make prior.
- Ensure your machine has Python installed. I am using python 3.8.2
- Install
thehive4pyby usingpip3 install thehive4py. I am using version 1.7.0.post1 - Download the
splunk-python-sdkand extract the contents - Add the SDK to the PYTHONPATH with
export PYTHONPATH=~/splunk-sdk-python - Create a file called ~/.splunkrc and populate it.
host=<SPLUNK HOST>
port=8089
username=<USERNAME>
password=<PASSWORD>
scheme=https
version=<SPLUNK VERSION>
The actual script
I will say that my Powershell skills are better than Python, and im sure that there are way of optimising it. I ran into a number of issues along the way here:
- Some fields are created by default and contain no values (such as updatedAt, updatedBy)
- Some fields are only created when they are required (such as endDate, resolutionStatus)
- In TheHive, custom fields are nested under the
customFieldspart of the data which presented a few challenges. For this writeup, I have called the customFieldscaseCfield1,caseCfield2andcaseCfield3. Change them to suit any required custom fields you have.
As a result, there needed to be extra validation logic added.
At a high level the script works as follows:
Get all the cases from TheHive
allCases = getCases(Gte('tlp',0),'all',[])Loop through each case
a. If certain fields don’t exist, add them with blank entries (updatedAt, updatedBy, endDate, resolutionStatus, impactStatus)
b. Look at the customFields and if they don’t exist, add them with blank entires (customField1, customField2, customField3)Put the case data into the kvstore
a. Check if the row already exists (or else a HTTP409 error is thrown) and if it doesn’t, then put the case data into the kvstore
b. if the row already exists, check if the updateAt field has been modified. If there is no modification, then pass over it or else delete the row so it can be rewritten.
c. perform acollection.data.insertto put the case data into the kvstore.As each case can contain multiple tasks, we get all the tasks, then loop through each one (inside the case loop)
a. To make the dashboard in Splunk I found it easier to add in some of the case particulars into each task (status, caseId, title, customField1, customField2, customField3)Put the task data into the kvstore
a. Check if the row already exists (or else a HTTP409 error is thrown) and if it doesn’t, then put the task data into the kvstore
b. if the row already exists, just discard it as case details may have changed
c. perform acollection.data.insertto put the task data into the kvstore
And with that out of the way… here is the script. Don’t forget to update the URL and API to your instance for TheHive.
#!/usr/bin/env python3
import sys, json
from splunklib.client import connect
from thehive4py.api import TheHiveApi
from thehive4py.query import *
try:
from utils import parse
except ImportError:
raise Exception("Add the SDK repository to your PYTHONPATH to run the examples "
"(e.g., export PYTHONPATH=~/splunk-sdk-python.")
api = TheHiveApi('<THEHIVE_URL','<THEHIVE_APIKEY>')
def main():
# Get all the cases by using TLP >0
allCases = getCases(Gte('tlp',0),'all',[])
cases_dict = json.loads(allCases)
for case in cases_dict:
# Check if there are any fields/customFields defined in the case that aren't generated by default. Give them '' if they don't exist
# Look for caseUpdateAt Field
if 'updatedAt' not in case:
case['updatedAt'] = ''
# Look for caseUpdateBy Field
if 'updatedBy' not in case:
case['updatedBy'] = ''
# Look for endDate Field
if 'endDate' not in case:
case['endDate'] = ''
# Look for caseResolutionStatus
if 'resolutionStatus' not in case:
case['resolutionStatus'] = ''
# Look for caseImpactStatus
if 'impactStatus' not in case:
case['impactStatus'] = ''
# Custom fields are a layer deep so we need some extra logic
# Look for custom1 Field
if 'custom1' in case['customFields']:
case['caseCfield1'] = case['customFields']['custom1'].get('string','')
else:
case['caseCfield1'] = ''
# Look for custom2 Field
if 'custom2' in case['customFields']:
case['caseCfield2'] = case['customFields']['custom2'].get('string','')
else:
case['caseCfield2'] = ''
# Look for custom3 Field
if 'custom3' in case['customFields']:
case['caseCfield3'] = case['customFields']['custom3'].get('string','')
else:
case['caseCfield3'] = ''
putData(case)
tasks = getTasks(case['_id'])
if tasks:
parsedTasks = (json.loads(tasks))
for task in parsedTasks:
# Borrow some fields from the case to add into the task row
task['caseStatus'] = case['status']
task['caseNum'] = case['caseId']
task['caseTitle'] = case['title']
task['caseCfield1'] = case['caseCfield1']
task['caseCfield2'] = case['caseCfield2']
task['caseOwner'] = case['owner']
# Write the data to the kvstore
putData(task)
def getCases(query, range, sort):
response = api.find_cases(query=query, range=range, sort=sort)
if response.status_code == 200:
return (json.dumps(response.json(), indent=4, sort_keys=True))
else:
print('ko: {}/{}'.format(response.status_code, response.text))
sys.exit(0)
def getTasks(query):
response = api.get_case_tasks(query)
if response.text != '[]':
return (json.dumps(response.json(), indent=4, sort_keys=True))
else:
return
def putData(data):
opts = parse(sys.argv[1:], {}, ".splunkrc")
opts.kwargs["owner"] = "nobody"
opts.kwargs["app"] = "search"
service = connect(**opts.kwargs)
collection_name = "TheHiveReporting"
collection = service.kvstore[collection_name]
writeRow = False
if(data['_type'] == 'case'):
# Check if the row exists (or else we get a HTTP409 error)
try:
# Query the row
caseUpdateReq = collection.data.query_by_id(data['_id'])
if(caseUpdateReq):
if(caseUpdateReq['caseUpdatedAt'] == str(data['updatedAt'])):
pass
else:
collection.data.delete_by_id(data['_id'])
writeRow = True
except:
writeRow = True
if(writeRow):
collection.data.insert(json.dumps({
'_key' : data['_id'],
'dataType' : 'case',
'parentId' : data['_id'],
'caseCreatedAt' : data['createdAt'],
'caseCreatedBy' : data['createdBy'],
'caseOwner' : data['owner'],
'caseUpdatedAt' : data['updatedAt'],
'caseUpdatedBy' : data['updatedBy'],
'caseEndDate' : data['endDate'],
'caseStatus' : data['status'],
'caseNum' : data['caseId'],
'caseTitle' : data['title'],
'caseDescription' : data['description'],
'caseSeverity' : data['severity'],
'caseResolutionStatus' : data['resolutionStatus'],
'caseImpactStatus' : data['impactStatus'],
'caseCfield1' : data['caseCfield1'],
'caseCfield2' : data['caseCfield2'],
'caseCfield3' : data['caseCfield3']
}))
elif(data['_type'] == 'case_task'):
taskOwner = data.get('owner', 'unassigned')
taskUpdatedAt = data.get('updatedAt', '')
taskUpdatedBy = data.get('updatedBy', '')
# Check if the row exists (or else we get a HTTP409 error)
# Were going to be a bit more brutal with tasks. If the row exists, blow it away and regenerate it as the case details may have changed.
try:
# Query the row
taskUpdateReq = collection.data.query_by_id(data['_id'])
if(taskUpdateReq):
collection.data.delete_by_id(data['_id'])
writeRow = True
except:
writeRow = True
if(writeRow):
collection.data.insert(json.dumps({
'_key' : data['_id'],
'dataType' : 'task',
'caseStatus' : data['caseStatus'],
'caseOwner' : data['caseOwner'],
'caseNum' : data['caseNum'],
'caseTitle' : data['caseTitle'],
'caseCfield1' : data['caseCfield1'],
'caseCfield2' : data['caseCfield2'],
'parentId' : data['_parent'],
'taskGroup' : data['group'],
'taskTitle' : data['title'],
'taskOwner' : taskOwner,
'taskCreatedAt' : data['createdAt'],
'taskCreatedBy' : data['createdBy'],
'taskUpdatedAt' : taskUpdatedAt,
'taskUpdatedBy' : taskUpdatedBy,
'taskStatus' : data['status']
}))
if __name__ == "__main__":
main()
Splunk Dashboard
Now that we have the data from TheHive into the Splunk kvstore, we can go about creating a dashboard to display it. This was a bit of an experience for me, as some of the Splunk queries took a lot of trial and error, this was on top of trying to figure out the best way structure the data in the kvstore as well.
I made the decision that if you owned the case, all the task data also showed up against the case owners name even if there was a different assignee. In your SOC’s you may find that the incident handler owns the case, but farms out tasks to others, however the ultimate responsibility is for the incident handler to manage the case to completion.
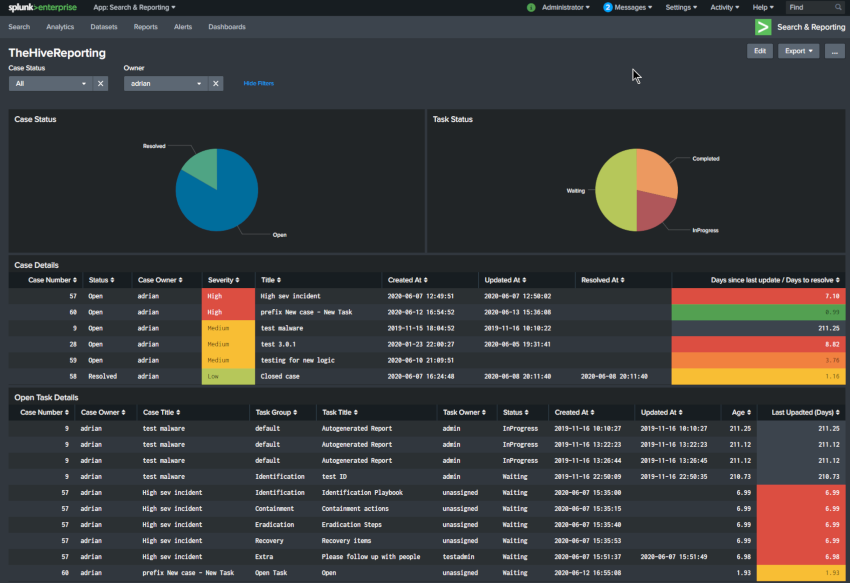
To get the dashboard up, just grab the xml code below and create a new dashboard.
<form theme="dark">
<label>TheHiveReporting</label>
<fieldset submitButton="false">
<input type="dropdown" token="caseStatus">
<label>Case Status</label>
<fieldForLabel>caseStatus</fieldForLabel>
<fieldForValue>caseStatus</fieldForValue>
<search>
<query>|inputlookup TheHiveReporting
|table caseStatus
|dedup caseStatus</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<default>Open</default>
<choice value="*">All</choice>
</input>
<input type="dropdown" token="owner">
<label>Owner</label>
<fieldForLabel>caseOwner</fieldForLabel>
<fieldForValue>caseOwner</fieldForValue>
<search>
<query>| inputlookup TheHiveReporting
|table caseOwner
|dedup caseOwner</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<choice value="*">All</choice>
<default>*</default>
</input>
</fieldset>
<row>
<panel>
<title>Case Status</title>
<chart>
<search>
<query>|inputlookup TheHiveReporting
| search dataType="case" caseStatus=$caseStatus$ caseOwner=$owner$
| stats count by caseStatus</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<option name="charting.axisTitleX.visibility">visible</option>
<option name="charting.axisTitleY.visibility">visible</option>
<option name="charting.axisTitleY2.visibility">visible</option>
<option name="charting.chart">pie</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">right</option>
<option name="refresh.display">progressbar</option>
<option name="trellis.enabled">0</option>
<option name="trellis.size">medium</option>
<option name="trellis.splitBy">_aggregation</option>
</chart>
</panel>
<panel>
<title>Task Status</title>
<chart>
<search>
<query>|inputlookup TheHiveReporting
| search caseOwner=$owner$ caseStatus=$caseStatus$ taskStatus!="Cancel"
|stats count by taskStatus</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<option name="charting.axisTitleX.visibility">visible</option>
<option name="charting.axisTitleY.visibility">visible</option>
<option name="charting.axisTitleY2.visibility">visible</option>
<option name="charting.chart">pie</option>
<option name="charting.drilldown">none</option>
<option name="charting.legend.placement">right</option>
<option name="refresh.display">progressbar</option>
<option name="trellis.enabled">0</option>
<option name="trellis.splitBy">taskStatus</option>
</chart>
</panel>
</row>
<row>
<panel>
<title>Case Details</title>
<table>
<search>
<query>|inputlookup TheHiveReporting
| search caseStatus=$caseStatus$ caseOwner=$owner$ dataType=Case
| eval Severity = case(caseSeverity==3,"High", caseSeverity==2,"Medium", caseSeverity==1,"Low")
| eval daysSinceLastUpdate=case(caseStatus="Open" AND caseUpdatedAt!="",round(((now() - (caseUpdatedAt/1000))/60/60/24),2), caseStatus="Open" AND caseUpdatedAt="",round(((now() - (caseCreatedAt/1000))/60/60/24),2))
| eval resolutionTime=case(caseStatus="Resolved",round((((caseEndDate/1000) - (caseCreatedAt/1000))/60/60/24),2))
| eval caseCreatedAt=strftime(caseCreatedAt/1000,"%Y-%m-%d %H:%M:%S")
| eval caseUpdatedAt=strftime(caseUpdatedAt/1000,"%Y-%m-%d %H:%M:%S")
| eval caseEndDate=strftime(caseEndDate/1000,"%Y-%m-%d %H:%M:%S")
| eval sort_severity=case(Severity="High",1, Severity="Medium",2, Severity="Low",3, caseCfieldType="",4)
| sort +sort_severity
| strcat daysSinceLastUpdate resolutionTime outputField
| table caseNum, caseStatus, caseOwner, Severity, caseTitle, caseCreatedAt, caseUpdatedAt, caseEndDate, sort_severity, outputField
| fields - sort_severity
| rename caseNum AS "Case Number", caseOwner AS "Case Owner", caseCreatedAt AS "Created At", caseUpdatedAt AS "Updated At", caseStatus AS "Status", caseTitle AS "Title", daysSinceLastUpdate AS "Last Updated (Days)", resolutionTime AS "Resolution Time (Hours)", caseEndDate AS "Resolved At", outputField AS "Days since last update / Days to resolve"</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<option name="drilldown">none</option>
<format type="number" field="caseSeverity">
<option name="precision">0</option>
</format>
<format type="color" field="Severity">
<colorPalette type="map">{"Medium":#F8BE34,"High":#DC4E41,"Low":#B6C75A}</colorPalette>
</format>
<format type="color" field="Type">
<colorPalette type="map">{"Incident":#DC4E41}</colorPalette>
</format>
<format type="color" field="Last Updated (Days)">
<colorPalette type="list">[#53A051,#006D9C,#F8BE34,#DC4E41,#3C444D]</colorPalette>
<scale type="threshold">1,3,5,14</scale>
</format>
<format type="color" field="Days since last update / Days to resolve">
<colorPalette type="list">[#53A051,#F8BE34,#F1813F,#DC4E41,#3C444D]</colorPalette>
<scale type="threshold">1,3,5,14</scale>
</format>
</table>
</panel>
</row>
<row>
<panel>
<title>Task Details</title>
<table>
<search>
<query>|inputlookup TheHiveReporting
| search caseStatus=$caseStatus$ taskStatus!="Cancel" taskStatus!="Completed" caseOwner=$owner$ OR taskOwner=$owner$
| eval taskAge=round(((now() - (taskCreatedAt/1000))/60/60/24),2)
| eval daysSinceLastUpdate=case(taskStatus!="Completed" AND taskUpdatedAt!="",round(((now() - (taskUpdatedAt/1000))/60/60/24),2), taskStatus!="Completed" AND taskUpdatedAt="",round(((now() - (taskCreatedAt/1000))/60/60/24),2))
| eval taskCreatedAt=strftime(taskCreatedAt/1000,"%Y-%m-%d %H:%M:%S")
| eval taskUpdatedAt=strftime(taskUpdatedAt/1000,"%Y-%m-%d %H:%M:%S")
|table caseNum, caseOwner, caseTitle, taskGroup, taskTitle, taskOwner, taskStatus, taskCreatedAt, taskUpdatedAt, taskAge, daysSinceLastUpdate
|sort - daysSinceLastUpdate
|rename caseNum AS "Case Number", caseTitle AS "Case Title", caseOwner AS "Case Owner", taskGroup AS "Task Group", taskTitle AS "Task Title", taskOwner AS "Task Owner", taskStatus AS "Status", taskCreatedAt AS "Created At", taskUpdatedAt AS "Updated At", taskAge AS "Age" daysSinceLastUpdate AS "Last Updated (Days)"</query>
<earliest>-24h@h</earliest>
<latest>now</latest>
</search>
<option name="drilldown">none</option>
<option name="refresh.display">progressbar</option>
<format type="color" field="Last Upadted (Days)">
<colorPalette type="list">[#53A051,#F8BE34,#F1813F,#DC4E41,#3C444D]</colorPalette>
<scale type="threshold">1,3,5,14</scale>
</format>
</table>
</panel>
</row>
</form>
Wrap up
I learnt quite a number of neat new tricks about Splunk spl, kvstore, thehive4py, and python during this exercise and I appreciate you taking the time to get this far. Extra points if you give it a go yourself and find any issues. Bonus points if you improve on it and release it.
References
thehive4py got a second wind
Splunk Lookup Editor
python-splunk-sdk
Splunk Tutorial: CRUDing a KV Store in Splunk Using Python