By Adrian | August 28, 2020
In my last post, I covered how I went about upgrading TheHive from 3.4 to 3.5RC1 along with a double upgrade of Elasticsearch. Well now its Cortex’s time. Cortex 3.1.0 also uses Elasticsearch 7.8 so we are in for a similar upgrade process.
Depending on your reliance on Cortex it may be a nice addition to TheHive that is rarely used, or it may be critical to your operation. Either way, getting to the latest version is desirable as there are always welcome bug fixes and improvements with error handling, reporting and general integration.
Table of Contents
- Table of Contents
- Caveats
- Current State to Future State
- Create a backup
- Upgrade ES 5.6 to ES 6.8
- Stop Cortex service
- Disable shard allocation
- Stop ES 5.6 service
- Perform upgrade to ES 6.8
- Upgrade any plugins
- Update ES 6.8 configuration
- Set $JAVA_HOME for ES
- Update the permissions of the
/etc/default/elasticsearchfile - Restart ES 6.8
- Check that ES is running
- Re-enable shard allocation
- Start Cortex
- Post ES 6.8 Upgrade - Test Cortex
- Perform migration from ES 6.8 to ES 7.8
- Install Prerequisite: JQ
- Identify if your index should be reindexed
- Make a note of the current indices on you Elasticsearch instance
- Stop Cortex service
- Create a new index
- Confirm
new_cortex_4index has been created - Reindex the data
- Post Reindex Check
- Delete old index
cortex_4 - Alias
new_cortex_4tocortex_4
- Upgade openjdk8 to openjdk11
- Upgrade to ES 7.8
- Install Docker
- Upgrade Cortex to 3.1.0 RC1
- Wrap up
Caveats
RC versions of Cortex are considered beta / pre-releases and are not suitable for production use as there may be unresolved or introduced bugs.
Use this guide at your own risk, and take precaution to look after your data and always test your upgrades on a duplicated instance so that you are familiar with the steps involved. That being said, I documented my steps, ironed out issues I came across and then did this upgrade a second time to test it out.
I am also no Elasticsearch expert, so my settings and steps may or may not be optimal.
This guide assumes that you running only Cortex on a single non-clustered server.
Current State to Future State
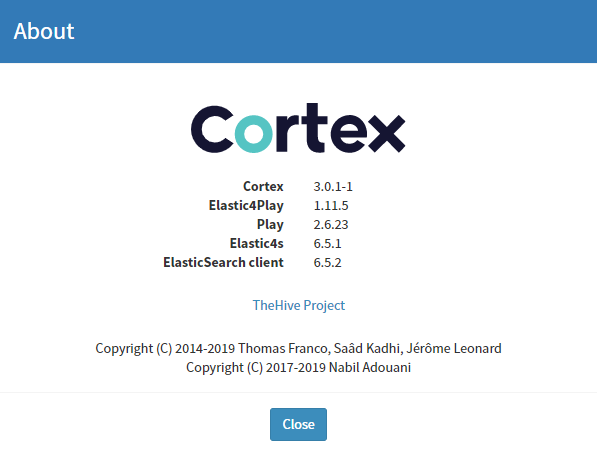
Prior to starting anything, be very sure and clear about what components are currently installed. For Cortex, this is as simple as doing an About from the interface. My current environment looks like this:
To check your current version of Elasticsearch drop to a shell where your Elasticsearch instance is and execute the following command:
curl http://localhost:9200
# Output
{
"name" : "Sf4T6UJ",
"cluster_name" : "hive",
"cluster_uuid" : "62l6IV_sR16kdp_qbRGaPw",
"version" : {
"number" : "5.6.16",
"build_hash" : "3a740d1",
"build_date" : "2019-03-13T15:33:36.565Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
Create a backup
Now is a great time to perform a backup and snapshot of your server, just in case you need to roll back.
First, create a backup of your Elasticsearch configuration.
sudo su
cd /etc/elasticsearch
cp elasticsearch.yml elasticsearch.yml.backup
My setup already includes the backup folder location and configurations for Elasticsearch, so skip that part if necessary. If you have not performed a backup, these are the steps to follow:
Create a backup folder location with the following command:
mkdir /opt/backup
# For some reason the 'other' group needed xx7 permission to the folder and im sure theres a tighter way to control this
chmod 777 /opt/backup
Edit the /etc/elasticsearch/elasticsearch.yml file and include the following line:
path.repo: ["/opt/backup"]
Now you will need to restart the Elasticsearch service if you updated the elasticsearch.yml file with the following:
sudo service elasticsearch restart
To perform the backup we need to get the index details, you do this by performing a web request to your Elasticsearch instance which may or may not be same box. Note the index in this case is cortex_4. The number refers to the schema version.
curl 'localhost:9200/_cat/indices?v'
# Output
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open cortex_4 CQOcr5UdSAexbrRCvEU4ng 5 1 2209 22 30.6mb 30.6mb
To register a snapshot use this command.
curl -XPUT 'http://localhost:9200/_snapshot/cortex_backup' -d '{
"type": "fs",
"settings": {
"location": "/opt/backup",
"compress": true
}
}'
# Output if successful:
{"acknowledged":true}
Create the backup by using this command (replace <INDEX> with the index identified earlier, in this case it will be cortex_4). You may also need to change your snapshot name <snapshot_2> if it already exists:
curl -XPUT 'http://localhost:9200/_snapshot/cortex_backup/snapshot_2?wait_for_completion=true&pretty' -d '{
"indices": "<INDEX>"
}'
# Output
{
"snapshot" : {
"snapshot" : "snapshot_2",
"uuid" : "AkCPqA-hS5WvG4lya-VyVg",
"version_id" : 5061699,
"version" : "5.6.16",
"indices" : [
"cortex_4"
],
"state" : "SUCCESS",
"start_time" : "2020-08-26T10:41:04.888Z",
"start_time_in_millis" : 1598438464888,
"end_time" : "2020-08-26T10:41:07.226Z",
"end_time_in_millis" : 1598438467226,
"duration_in_millis" : 2338,
"failures" : [ ],
"shards" : {
"total" : 5,
"failed" : 0,
"successful" : 5
}
}
}
As I am using Hyper-V as my virtualisation layer, I have also created a snapshot of the server at this point for worst case failure. The same principals apply for esx-i, XenServer, VirtualBox, ProxMox etc.
Upgrade ES 5.6 to ES 6.8
Stop Cortex service
Stop the Cortex service using the following commands:
sudo service cortex stop
sudo service cortex status
Disable shard allocation
Use the following command to disable shard allocation. My understanding is that this should not be required if we are running in a single node configuration as per Cluster Level Shard Allocation
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}'
# Output
{"acknowledged":true,"persistent":{"cluster":{"routing":{"allocation":{"enable":"none"}}}},"transient":{}}
curl -X POST "localhost:9200/_flush/synced"
# Output
{"_shards":{"total":20,"successful":10,"failed":0},"cortex_4":{"total":10,"successful":5,"failed":0}}
Stop ES 5.6 service
sudo service elasticsearch stop
sudo service elasticsearch status
Perform upgrade to ES 6.8
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo apt-get install apt-transport-https
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
sudo apt-get update && sudo apt-get install elasticsearch
If prompted that the elasticsearch.yml has been modified select N
Upgrade any plugins
In my case I did not have any plugins to upgrade. But these are the commands to use:
/usr/share/elasticsearch/bin/elasticsearch-plugin list
## for all plugin:
/usr/share/elasticsearch/bin/elasticsearch-plugin install $plugin
Update ES 6.8 configuration
Add the following 2 lines to the end of your /etc/elasticsearch/elasticsearch.yml file
path.logs: "/var/log/elasticsearch"
path.data: "/var/lib/elasticsearch"
Comment out the line for script.inline: true as it is not required.
Set $JAVA_HOME for ES
Find the path of your JavaJDK installation. For me, my installation was in /usr/lib/jvm/java-8-openjdk-amd64
Update /etc/default/elasticsearch and uncomment the JAVA_HOME setting and add your java path in. ie:
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
Update the permissions of the /etc/default/elasticsearch file
If you attempt to restart Elasticsearch at this point, the service will fail with the following error:
elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Wed 2020-08-19 06:22:08 UTC; 5s ago
Docs: http://www.elastic.co
Process: 3094 ExecStart=/usr/share/elasticsearch/bin/elasticsearch -p ${PID_DIR}/elasticsearch.pid --quiet (code=exited, status=1/FAILURE)
Main PID: 3094 (code=exited, status=1/FAILURE)
Aug 19 06:22:08 thehive systemd[1]: Started Elasticsearch.
Aug 19 06:22:08 thehive elasticsearch[3094]: /usr/share/elasticsearch/bin/elasticsearch-env: line 71: /etc/default/elasticsearch: Permission denied
Aug 19 06:22:08 thehive systemd[1]: elasticsearch.service: Main process exited, code=exited, status=1/FAILURE
Aug 19 06:22:08 thehive systemd[1]: elasticsearch.service: Failed with result 'exit-code'.
This can be corrected by fixing the permissions on the file.
chmod o+r /etc/default/elasticsearch
Restart ES 6.8
Use the following commands to enable Elasticsearch on restart and to manaully start the service now:
sudo update-rc.d elasticsearch defaults 95 10
sudo service elasticsearch start
sudo service elasticsearch status
Check that ES is running
Now with all the required Elasticsearch configuration completed, all going well you should be able to execute the following command to check the installation. Note that the version is now 6.8.12.
curl -X GET "localhost:9200/"
# Output
{
"name" : "Sf4T6UJ",
"cluster_name" : "hive",
"cluster_uuid" : "62l6IV_sR16kdp_qbRGaPw",
"version" : {
"number" : "6.8.12",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "7a15d2a",
"build_date" : "2020-08-12T07:27:20.804867Z",
"build_snapshot" : false,
"lucene_version" : "7.7.3",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
If you try this command before Elasticsearch has had a chance to start fully you will see this error. Try it again after a few seconds:
curl: (7) Failed to connect to localhost port 9200: Connection refused
Re-enable shard allocation
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}'
# Output
{"acknowledged":true,"persistent":{},"transient":{}}
Start Cortex
You can start Cortex with the following commands:
sudo service cortex start
sudo service cortex status
Post ES 6.8 Upgrade - Test Cortex
At this point, we have completed the first part of this process…upgrading ElasticSearch from 5.6 to 6.8. Test that you can login to Cortex without and issues and perform some basic sanity tests.
It is advisable to create a snapshot of your server at this time before you progress to the next part of the upgrade.
Perform migration from ES 6.8 to ES 7.8
Install Prerequisite: JQ
Having the jq package installed makes parsing json formatting so much easier!
sudo apt-get install -qy jq
Identify if your index should be reindexed
As my original installation of Cortex was done under ES 5.6 environment, my data will require a reindex so that it can be read by ES 7.8. If you started your journey with Cortex prior to version 3.0 then there is a fairly good chance that this is going to be required. This can be confirmed by running the following command:
curl -s http://127.0.0.1:9200/cortex_4?human | jq '.cortex_4.settings.index.version.created_string'
# Output
"5.6.16"
If you are showing 5.6.x then you will need to perform a reindex.
Make a note of the current indices on you Elasticsearch instance
curl http://localhost:9200/_cat/indices\?v
# Output
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open cortex_4 CQOcr5UdSAexbrRCvEU4ng 5 1 2209 22 30.6mb 30.6mb
Stop Cortex service
Shutdown Cortex service using the following command:
sudo service cortex stop
sudo service cortex status
Create a new index
We need to create a new index with the same settings as our existing index. Using the official migration guide from TheHive has this command with \ separated lines. I found that this did not create the index correctly and threw an error error: syntax error, unexpected INVALID_CHARACTER (Unix shell quoting issues?) at <top-level>, line 1:
Stripping out the \ line breaks and running it as a single line command did the trick for me.
curl -XPUT 'http://localhost:9200/new_cortex_4' -H 'Content-Type: application/json' -d "$(curl http://localhost:9200/cortex_4 | jq '.cortex_4 | del(.settings.index.provided_name,.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.mapping.single_type,.mappings.doc._all)' )"
# Output
{"acknowledged":true,"shards_acknowledged":true,"index":"new_cortex_4"}
Confirm new_cortex_4 index has been created
Note that the docs.count for the new index is 0. At this time we have only created a new index.
curl -XGET http://localhost:9200/_cat/indices\?v
# Output
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open new_cortex_4 cq8VwTANTAi95d5zh8Josg 5 1 0 0 1.1kb 1.1kb
yellow open cortex_4 CQOcr5UdSAexbrRCvEU4ng 5 1 2209 22 30.6mb 30.6mb
Reindex the data
The following command reindexes the data from cortex_4 index to new_cortex_4 index.
curl -XPOST -H 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"conflicts": "proceed",
"source": {
"index": "cortex_4"
},
"dest": {
"index": "new_cortex_4"
}
}' | jq
# Output
{
"took": 3912,
"timed_out": false,
"total": 2203,
"updated": 0,
"created": 2203,
"deleted": 0,
"batches": 3,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
If you receive json data that contains failure, DO NOT PROCEED, there is a good chance that the migration stopped on the first error. To start with, check the command you used create new_cortex_4. Use a tool such as Kaizen if you are unfamiliar with querying Elasticsearch from a curl command. Check that the database schema was created correctly.
Post Reindex Check
Check the status of the reindex with the following command:
curl -XGET http://localhost:9200/_cat/indices\?v
# Output
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open new_cortex_4 cq8VwTANTAi95d5zh8Josg 5 1 2209 0 30.3mb 30.3mb
yellow open cortex_4 CQOcr5UdSAexbrRCvEU4ng 5 1 2209 22 30.6mb 30.6mb
Note that the docs.count match. If there was an error these values would not match and you would have data loss.
Delete old index cortex_4
Now we have confirmed that the docs.count values match and that the reindex was a success, delete any old existing indexes with the following command:
curl -XDELETE http://localhost:9200/cortex_4
# Output
{"acknowledged": true}
IMPORTANT: Elasticsearch will not start if there is an index that was created in an older version of ES.
Alias new_cortex_4 to cortex_4
curl -XPOST -H 'Content-Type: application/json' 'http://localhost:9200/_aliases' -d '{
"actions": [
{
"add": {
"index": "new_cortex_4",
"alias": "cortex_4"
}
}
]
}'
# Output
{"acknowledged":true}
Confirm this with the following command:
curl -XGET http://localhost:9200/_alias?pretty
# Output
{
"new_cortex_4" : {
"aliases" : {
"cortex_4" : { }
}
}
}
Upgade openjdk8 to openjdk11
When I started ES 7.8 on my first run, I started getting warnings about JDK8, so I thought i’d upgrade it prior.
[cortex] future versions of Elasticsearch will require Java 11; your Java version from [/usr/lib/jvm/java-8-openjdk-amd64/jre] does not meet this requirement
It can upgrade it with the following command:
sudo apt-get install openjdk-11-jre-headless
Upgrade to ES 7.8
Keep going, were nearly there!
Update /etc/elasticsearch/elasticsearch.yml file
Create a backup of the elasticsearch.yml file with the following command:
sudo cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.es68
Make the following configuration changes to /etc/elasticsearch/elasticsearch.yml:
network.host: 127.0.0.1
cluster.name: hive
# thread_pool.index.queue_size: 100000 # ES 6
thread_pool.search.queue_size: 100000 # ES 7
# thread_pool.bulk.queue_size: 100000 # ES 6
thread_pool.write.queue_size: 10000 # ES 7
path.repo: ["/opt/backup"]
path.logs: "/var/log/elasticsearch"
path.data: "/var/lib/elasticsearch"
node.data: true
discovery.type: single-node
Disable Shard Allocation
Once again, I beleive that this only applies to clustered environments.
curl -X PUT "localhost:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}'
curl -X POST "localhost:9200/_flush/synced?pretty"
Stop ES 6.8
We must stop Elasticsearch in order to upgrade it. Use the following commands:
sudo service elasticsearch stop
sudo service elasticsearch status
Upgrade ES 6.8 to 7.8
Use the following commands to upgrade Elasticsearch to 7.8
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo apt-get install apt-transport-https
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
sudo apt-get update && sudo apt-get install elasticsearch
If prompted that the files have been modified select N. I was prompted about the following files:
/etc/elasticsearch/elasticsearch.yml/etc/default/elasticsearch
Update $JAVA_HOME for ES 7.8
Now that we have updated JDK to version 11, we need to update the /etc/default/elasticsearch file and change the JAVA_HOME setting from java-8 to java-11.
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
Upgrade any plugins (ES7.8)
In my case I did not have any plugins to upgrade
/usr/share/elasticsearch/bin/elasticsearch-plugin list
## for all plugin:
/usr/share/elasticsearch/bin/elasticsearch-plugin install $plugin
Start ES 7.8
sudo service elasticsearch start
sudo service elasticsearch status
Re-enable shard allocation (ES 7.8)
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}'
Install Docker
Analyzers and Responders are moving down the path of Docker. My current installation does not have docker. I beleive that Docker is optional at this time. There is also additional configuration to enable the Docker analyzers and Responders in the application.conf file. I won’t be making that configuration change at this time.
Install Docker prereqs
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
Add the Docker GPG Keys
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
Check the fingerprint of the key
sudo apt-key fingerprint 0EBFCD88
# Output
pub rsa4096 2017-02-22 [SCEA]
9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88
uid [ unknown] Docker Release (CE deb) <docker@docker.com>
sub rsa4096 2017-02-22 [S]
Add the stable repository
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
Install Docker and Docker Compose
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose
Check installed version
sudo docker version
Manage docker as a non root user
Having to sudo every docker command on the command line is annoying and may not allow Cortex to run its analyzers and responders, so create a docker group and add the cortex user into it. You will need to logoff and on again for the group to re-evaluate.
sudo usermod -aG docker cortex
Upgrade Cortex to 3.1.0 RC1
For my particular installation I have used the extracted binaries, so I used the following steps to upgrade. At this time double check that the cortex service is still stopped.
sudo service cortex status
Add PGP Keys
cd /opt
curl https://raw.githubusercontent.com/TheHive-Project/cortex/master/PGP-PUBLIC-KEY | sudo apt-key add -
Download Cortex 3.1.0 RC1
wget https://download.thehive-project.org/cortex-beta-latest.zip
Extract Cortex 3.1.0 RC1
sudo unzip cortex-beta-latest.zip
Break the Symlink
sudo rm cortex
sudo ln -s cortex-3.1.0-RC1-1 cortex
Copy over the existing application.conf file
sudo cp /opt/cortex-3.0.1-1/conf/application.conf /opt/cortex/conf/
Fix permissions on /opt/cortex
As my Cortex installation runs under the cortex user account, the cortex user needs to own the files/directories so that it can start successfully. After Extracting the files the owner was root so when I started Cortex the service exited with an error.
cd /opt/cortex
sudo chown -R cortex:cortex *
Restart Cortex 3.1.0 RC1
Now we have extracted the binaries, updated the Symlink and recopied over the application.conf file, the last step is to start Cortex and perform a DB update.
sudo service cortex start
sudo service cortex status
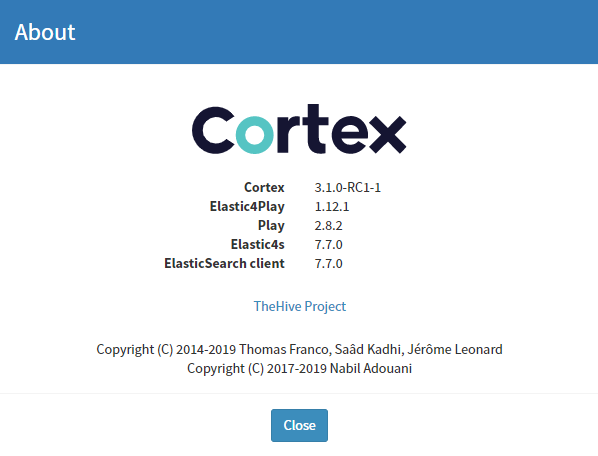
Validate Cortex 3.1.0 RC1
Its at this point Cortex is on the latest version of 3.1.0 RC1. The migration notes for TheHive made a mention that there should be a cortex_5 index in elasticsearch as a result of this upgrade, and this was something that I was just not seeing. I retraced my installation, reverted snapshots, attempted to manually trigger the DB maintenance process, re-tried my installation, performed a clean build of Cortex 3.1.0RC directly. I even deleted the existing Cortex indexes in elasticsearch. Everytime, all the logs indicated cortex_4. I reached out to the @TheHive-Project who advised there is a typo in that particular guide. You know what though? I learnt a little more about Cortex as a result of all the troubleshooting and rebuilding.
Login to Cortex and check the version. You should now be on the latest beta.
It is at this point that you should also login to TheHive and check that you can still run analyers and responders.
Wrap up
Just as TheHive upgrade, its a fairly lengthy upgrade process. But if you have upgraded TheHive, then 90% of the process is the same. I would still advise to stand up a test system, restore live data to it and try it out under safe conditions. Once Cortex 3.1 comes out of Release Candidate, upgrading it should be just a matter of upgrading the binaries. This guide should still be relevant if your not going to the RC first.